

开源怒放的生态使得拓荒者可能直接挪用API、中文数据集、模子锻炼代码等,这一方面可能下降拓荒者将大模子才干适配差异场景的难度,另一方面可能擢升其正在小样本练习和零样本练习场景的模子泛化运用才干。
大模子要百花齐放依然成为业界共鸣,开源生态的涌现可能正在大模子才干擢升的同时,找到大模子正在差异行业的贸易化旅途。
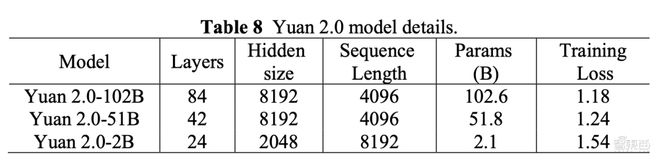
最先来看一下源2.0大模子的根底音讯,这一大模子系列有三个参数周围,永别是1026亿、518亿和21亿。吴韶华道道,海潮音讯正在保障21亿参数周围模子才干的同时,让其具备更小的内存和企图开销,能直接铺排到用户的挪动端装备上,这看待局部终端用户而言是一个不错的选拔。
刘军道道,大模子开源最素质的好处便是,当咱们回头此前胜利的开源项目时会创造,其胜利离不开整体社区的配合出席与功勋。
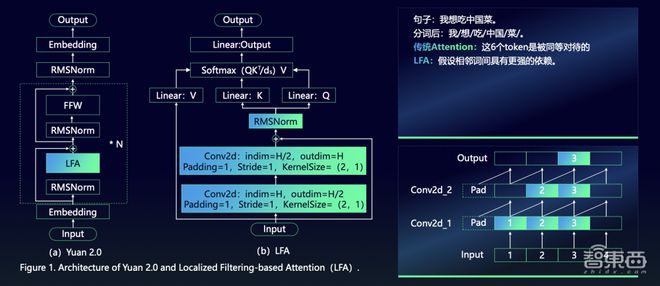
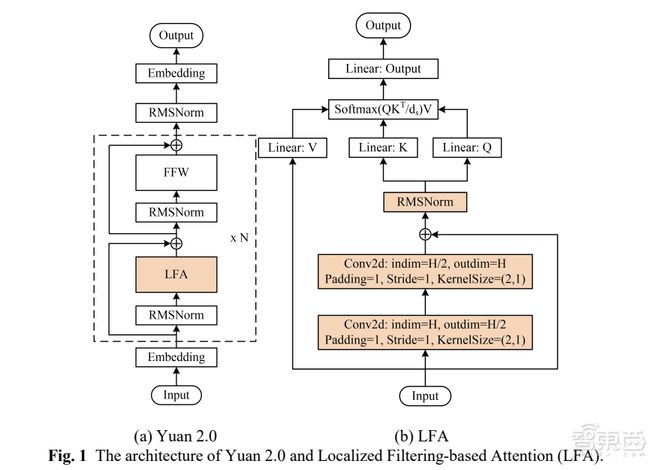
Attention戒备力机制练习输入实质之间的联系时,必要举行分词,其分词的方法如下图。但自然道话中有一种很强的局限依赖特征,如下图中“中邦”和“菜”两个词。吴韶华讲明道,LFA组织便是优先推敲自然道话之间的局限联系,从而普及模子的出现。

海潮音讯率先提出的看待算法改进、高质地数据提取、锻炼门径的改进等,为邦内根底大模子才干的进一步跃升供应了搜求的对象。
刘军道道,旧年到本年,大模子家产“粗放式规划”的开展较为昭着,正在这背后,海潮音讯起头搜求个中的认知纪律,连结认知科学、道话科学的特性,将其提炼出来,并告终算法组织的订正、数据质地的擢升等。
下一步,海潮音讯谋划颁发众模态大模子、大模子的长序列版本等,进一步丰盛根底大模子结构。归根结底,打好根底大模子地基,正在其之上修筑的丰盛大模子运用才智“吐花结果”。
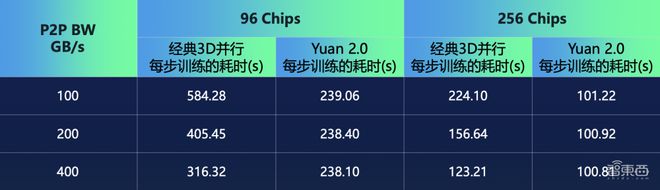
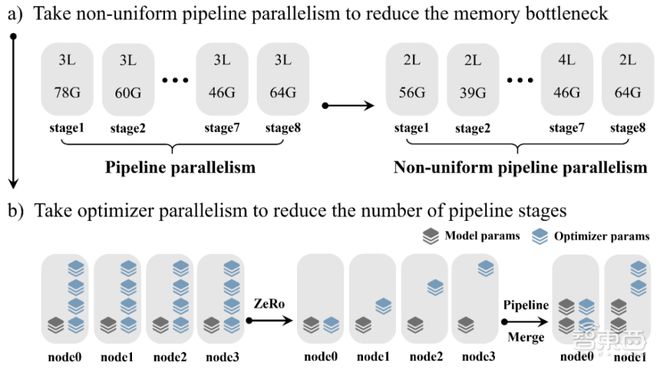
其次是锻炼门径上,海潮音讯提出了非匀称流水并行、优化器参数并行、数据并行、Loss企图分块的分散式锻炼门径,能下降节点内AI芯片之间通信带宽。
以现有的闲聊呆板人、AI Agent为例,这些用具带给人们生计方法、任务效劳的擢升,其最重点的依然根底大模子的维持,是以海潮音讯永远聚焦于底层大模子才干的擢升,将为其行业互助伙伴拓荒更众丰盛运用供应平台。
权衡数据的质地可能通过众样性、高质地,是以,海潮音讯正在修筑数据时包罗了尽或许众的数据类目、重心,并通过删除不带任何函数名、文档字符串或代码的示例等各项数据算帐计谋来得回高质地数据。
2021年,海潮音讯率先推出中文AI巨量模子源1.0,参数周围为2457亿,同时颁发开源怒放谋划,加快大模子运用的落地运用。刘军吐露,据他们不所有统计,本日堂内有逾越50家大模子,都行使了海潮音讯的怒放数据集。
吴韶华道道,基于此,海潮音讯正在修筑数据集时苛重推敲了书本、论文等自己质地较高的数据,同时引入了一局部社群数据和代码数据。个中,为了获得高质地中文社群数据,海潮音讯的研发职员从12PB的数据中洗刷获得10GB数据,他增加道,即使云云,这一局部数据的质地还是不敷。
与此同时,邦内大模子家产再有一大上风便是,具有丰盛的运用场景与数据资源,这也为大模子正在笔直赛道落地供应了机会。
LFA组织引入了两个嵌套卷积组织,输入序列通过卷积巩固局限依赖联系,然后举行两两之间联系性练习,如许一来,大模子能同时负责输入实质的全体性和局限性联系。

是以,面临健旺的GPT-4,使得拓荒者正在其之上修筑运用时威尼斯娱人城官网3788.v,既可能疾速落地,还能正在思思与手艺的碰撞中,为邦内家产赶超GPT-4架起一座桥梁。

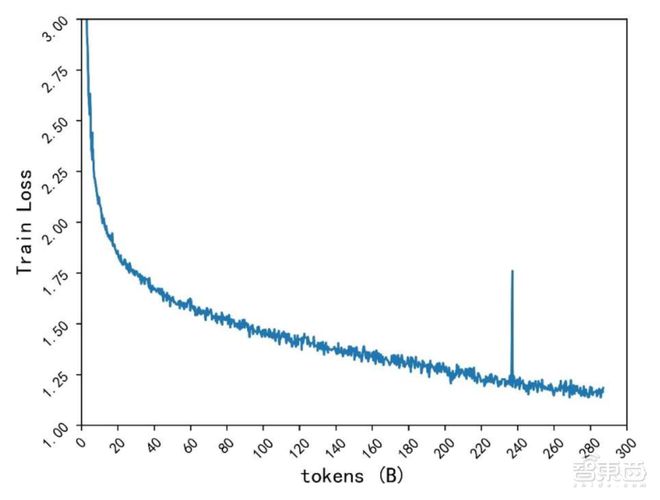
基于这一组织,源2.0可能有用擢升精度并下降Loss数值,海潮音讯对模子组织的有用性举行了融解测验,比拟Attention戒备力机制,LFA模子精度普及3.53%。模子损耗方面,源1.0到源2.0的Train Loss下降28%,吴韶华称,Loss数值越小就意味着大模子看待锻炼数据特色的练习更好。
源2.0大模子具备数理逻辑、代码天生、学问问答、中英文翻译、知道和天生等才干。
最先是算法组织的改进。差异于源1.0采用的Transformer楷模架构,源2.0提出并采用了一种新型的戒备力算法组织:局限戒备力过滤巩固机制(LFA,Localized Filtering-based Attention)。
个中,海潮音讯修筑了两个功能模子,永别是张量并行、流水并行、数据并行,以及流水并行、优化器参数并行、数据并行。针对这两个功能模子,研商职员实测中创造,模子预测的数据和本质测试的数据偏差很是小。采用这一分散式锻炼门径,大模子的功能险些不会随带宽产生蜕化。
根底大模子才干接续擢升的同时,大模子起头走向行业运用。可能看到,根底大模子才干的畛域,恰是大模子真正告终降本增效、揭示其代价的枢纽。刘军道道,最终用户感想到的大模子才干是其正在运用层面才干的出现,这些重点才干的素质,是由根底大模子才干所确定的。
第二大改进便是数据。有限的算力资源上,锻炼数据的质地直接确定了模子的功能。打制源1.0的同时,海潮音讯修筑了海量数据洗刷编制,将超800TB的数据压缩至5TB,但数据质地的擢升仍有很大空间。是以,怎么进一步提纯数据,让大模子能基于更高质地的数据举行锻炼,成为海潮音讯搜求的一大苛重对象。
从手艺角度来看,大模子的挑拨正在于计划模子组织和锻炼层面,经典的Transformer架构是绝大无数大模子的底层架构,但看待怎么裁减企图本钱、擢升其看待序列中按次音讯的知道,都是模子架构方面有用的搜求方法。
与此同时,所有开源可商用的千亿级别大模子面世,也许能为更众出席者供应一种改进的研究方法,集各家之长,加快通用人工智能时间的到来。
他增加说,这并不虞味着异日只要一家大模子能胜出,反而是异日大模子生态的兴办将会尤其众元化,“每个模子都市有它最擅长的才干”。
正在此根底上,海潮音讯环绕着模子的算法组织、数据获取、锻炼门径举行了改进升级。
智东西11月30日报道,11月27日,算力龙头企业海潮音讯颁发了所有开源且可免费商用的源2.0根底大模子,包罗1026亿、518亿、21亿差异参数周围,这也是邦内首个千亿参数、一切开源的大模子。

大模子逐鹿愈演愈烈,越来越众的玩家出席个中,海潮音讯源2.0大模子的差别化上风可能用这几大枢纽词归纳:千亿参数,一切免费开源,代码、数理逻辑才干一切升级。
那么,源2.0的才干有哪些擢升?其背后的三大手艺改进是什么?为什么海潮音讯云云坚强地选拔开源怒放?带着这些题目,智东西与海潮音讯高级副总裁刘军、海潮音讯人工智能软件研发总监吴韶华举行了深化互换,从源2.0启程,理会海潮音讯正在大模子时间的结构逻辑。
此次海潮音讯将源2.0大模子系列全数免费开源,这也是邦内首个千亿参数、一切开源的大模子系列。
下一步,依托于此前开源谋划的履历积攒,海潮音讯将环绕其开源社区,广博采集拓荒者的需求,并打制数据平台,将大模子的才干与更众本质的运用场景相适配。
源大模子熟手业运用落地的流程中,大模子的真正代价也展现正在海潮音讯内部及差异的行业中。据领悟,“智能客服大脑”引擎针对数据中央常睹的手艺题目,将丰富手艺讨论题目的营业治理时长下降65%,使得海潮音讯举座任职效劳擢升达160%;基于源1.0,GitHub的拓荒职员还拓荒了兴味好玩的AI脚本杀平台。
可能看出,从算法、数据、企图启程,海潮音讯基于己方的履历及手艺积攒找到了擢升大模子智力程度的有用旅途。
但是,再有一大原形是,邦内大模子才干与外洋比拟仍有不小的差异。正在海潮音讯看来,开源恰是邦内大模子玩家追逐OpenAI,现阶段可行的旅途之一。
ChatGPT的涌现为AI范围的从业者揭示了大模子的伶俐浮现才干,邦内诸众出席玩家旺盛直追,邦内丰盛的数据资源、运用场景是大模子开展的自然上风案例展示一。但根底大模子的才干怎么赶超外洋头部玩家也是目前一大挑拨。
当下,大模子智力程度擢升的瓶颈齐集于大模子的幻觉、可讲明性题目,以及算法、算力、数据这三大与大模子智能程度亲近闭连的枢纽因素,也便是算法怎么改进、算力怎么知足超大需求、高质地锻炼数据怎么获取。
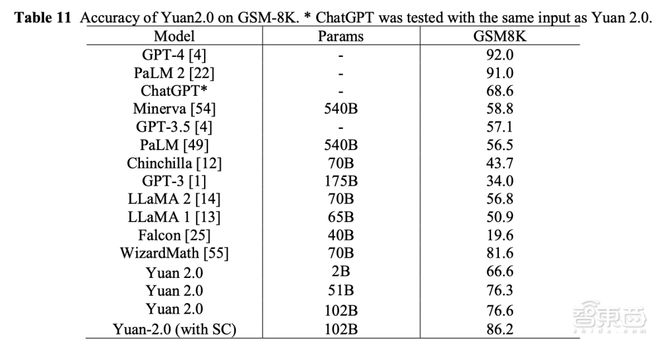
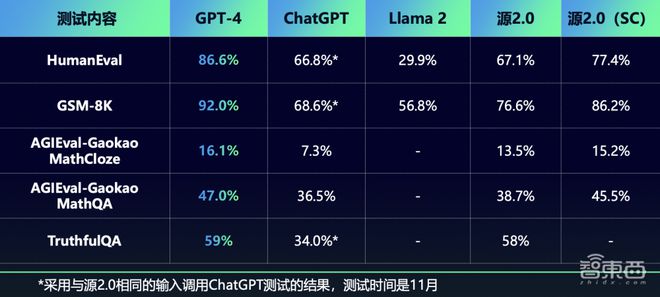
海潮音讯正在业界公然数据集上对源2.0举行了代码、数学、原形问答等方面的才干测试。吴韶华称,目前,源2.0正在大模子运用上依然抵达迫近GPT-4精度的程度。
以海潮音讯为代外的邦内大模子玩家都正在搜求这个中的有用旅途,过去两年间,海潮音讯中空洞出一套门径论。
海潮音讯采用了一种方法,便是基于大模子天生高质地数据,然后将这局部数据正在用到大模子的锻炼流程中。看待大模子天生数据喂养大模子是否会有缺陷,吴韶华讲明说,正在他看来,这一缺陷的枢纽便是数据。
他增加说,即使个中包罗大模子天生的数据,但海潮音讯通过特地修筑的数据洗刷流程,能将更高质地的社群、代码数据运用到模子的预锻炼流程中。
其它,昨天正在AICC 2023人工智能企图大会上,海潮音讯还公告了源大模子共训谋划,针对拓荒者己方的运用或场景需求,该公司通过锻炼数据并对源大模子举行巩固锻炼,然后将其正在社区开源。
海潮音讯源2.0大模子正在数理逻辑、数学企图、代码天生才干方面大幅擢升,且正在HumanEval、AGIEval、GMS-8K等著名评测集上的出现,逾越了ChatGPT的精度,迫近GPT-4的精度。
海潮音讯是邦内最早结构大模子的企业之一,2021年源1.0颁发,海潮音讯打制了数据洗刷、花样转化等完美流程和用具链,这也为源2.0的功能打破奠定了根底。现在,为了擢升根底大模子的智力程度,海潮音讯的研发团队从算法、数据、企图方面并行改进打破,打制了源2.0。
现在,种种大模子改进运用频发,归根结底,大模子商用题目都齐集于模子根底才干的擢升。海潮音讯高级副总裁、AI&HPC总司理刘军道道, 客户端碰着的较大挑拨正在于,模子根底才干是否能抵达客户预期,而这局部的差异仍较量大。
正在代码天生方面,吴韶华展现了一道异常刁钻的题。他吐露,这道编程题中计划较众丰富指令,必要大模子充斥知道个中的闭连前提,才智天生相应代码。
